使用 AnythingLLM 创建个人知识库
2025-05-01 by dongnan
环境描述
- Ollama: v0.6.2
- DeepSeek-R1:14b
- AnythingLLM: v1.7.8
测试平台
CPU: i7-11700K
内存: 32.0 GB
显卡: NVIDIA GeForce RTX 3070
磁盘: 1TB SSD
系统: Windows 11
开始之前
什么是 LLM与Ollama?
详细说明请参考这里
什么是 向量数据库?
向量数据库(Vector Database)是一种专门设计用来存储、管理和检索向量数据(通常是高维向量)的数据库。
向量数据通常来自于机器学习模型,尤其是自然语言处理(NLP)模型或计算机视觉模型,这些模型将文本、图像、音频等非结构化数据转换为向量表示(Embedding),从而使得这些数据能够在数值空间中进行比较、检索和分析。
什么是 Embedding Model?
Embedding Model 是一种用于将数据(通常是文本)转换为高维向量的模型,使得这些数据能够在向量空间中进行处理。
Embedding(嵌入)是将高维数据(如单词、句子或整个文档)映射到一个低维的向量空间中,同时保持这些数据的语义信息和关系。
Embedding在NLP(自然语言处理)中扮演着至关重要的角色,它在很多任务中起到了关键作用,特别是在处理语义理解和相似性计算时。
什么是 RAG ?
RAG(Retrieval-Augmented Generation,检索增强生成)技术结合了信息检索与文本生成,用于提高生成模型的质量和准确性。 通过整合外部知识库(如文档库、数据库或网络信息),RAG能够帮助模型基于更广泛的背景知识生成更精准和相关的答案。
AnythingLLM
AnythingLLM 是一个全栈应用,能够将不同格式的文档(如 PDF、TXT、DOCX 等)或内容片段转化为上下文,供大语言模型(LLM)在聊天过程中作为参考。 此应用程序支持选择使用不同的 LLM 或向量数据库。
部署
下载及安装过程 参考这里
创建工作空间
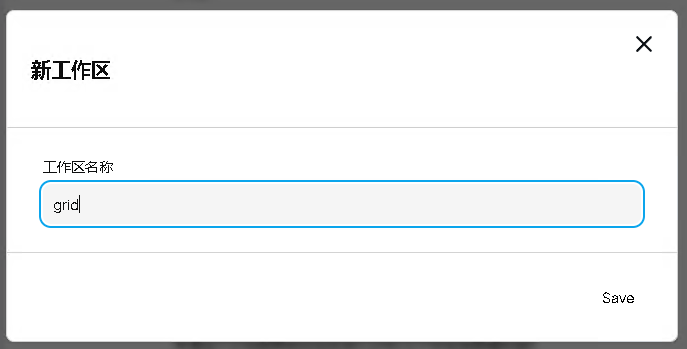
接下来创建工作空间,这里创建一个名字为 grid 的空间,如下所示:
配置
然后开始进行配置,点击左下角扳手
-
配置LLM:
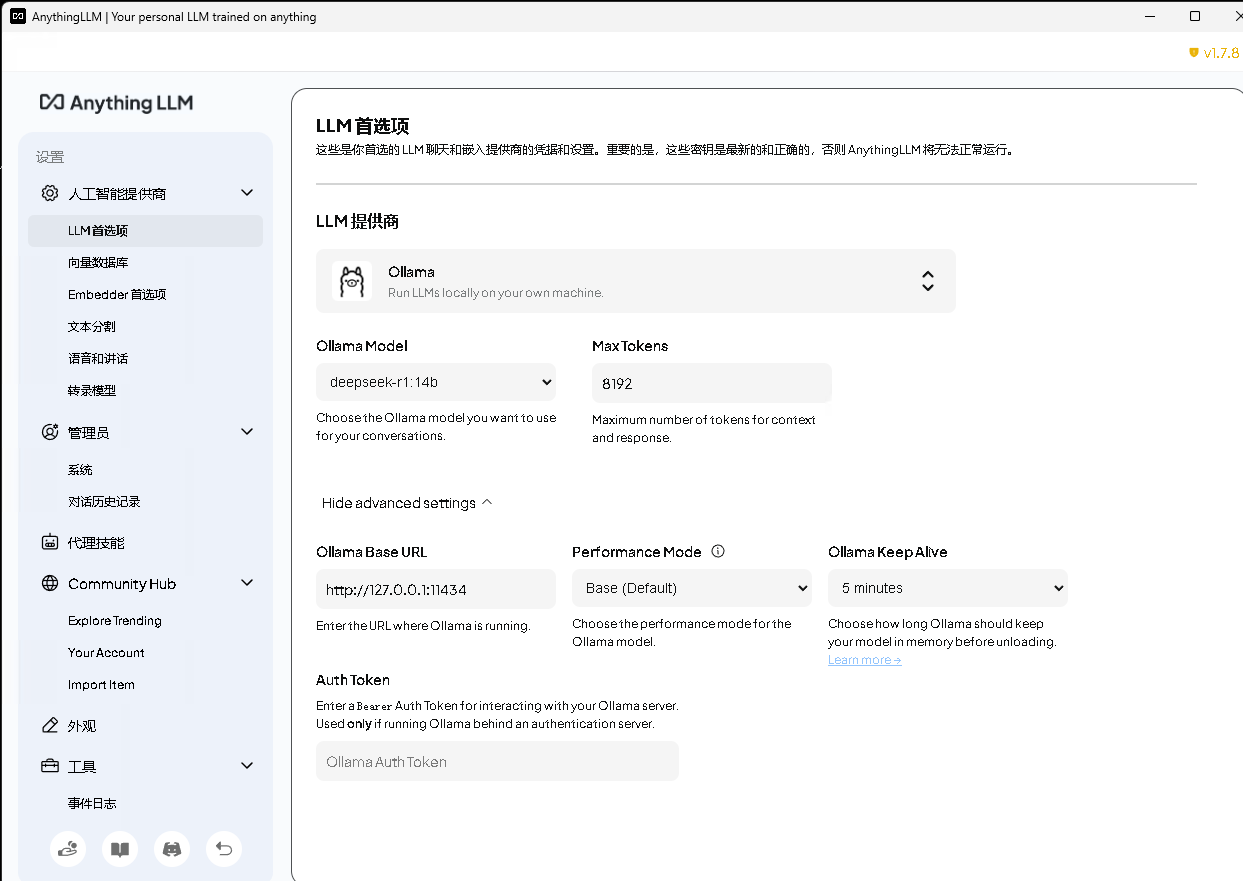
- LLM 提供商为 Ollama
- Ollama 模型为 DeepSeek-R1:14b
- token 长度为 8192
- Ollama 地址为 http://127.0.0.1:11434
- 更改点击右上角的保持更改选项
-
向量数据库:
- 保持默认的
LanceDB即可。
- 保持默认的
-
嵌入模型:
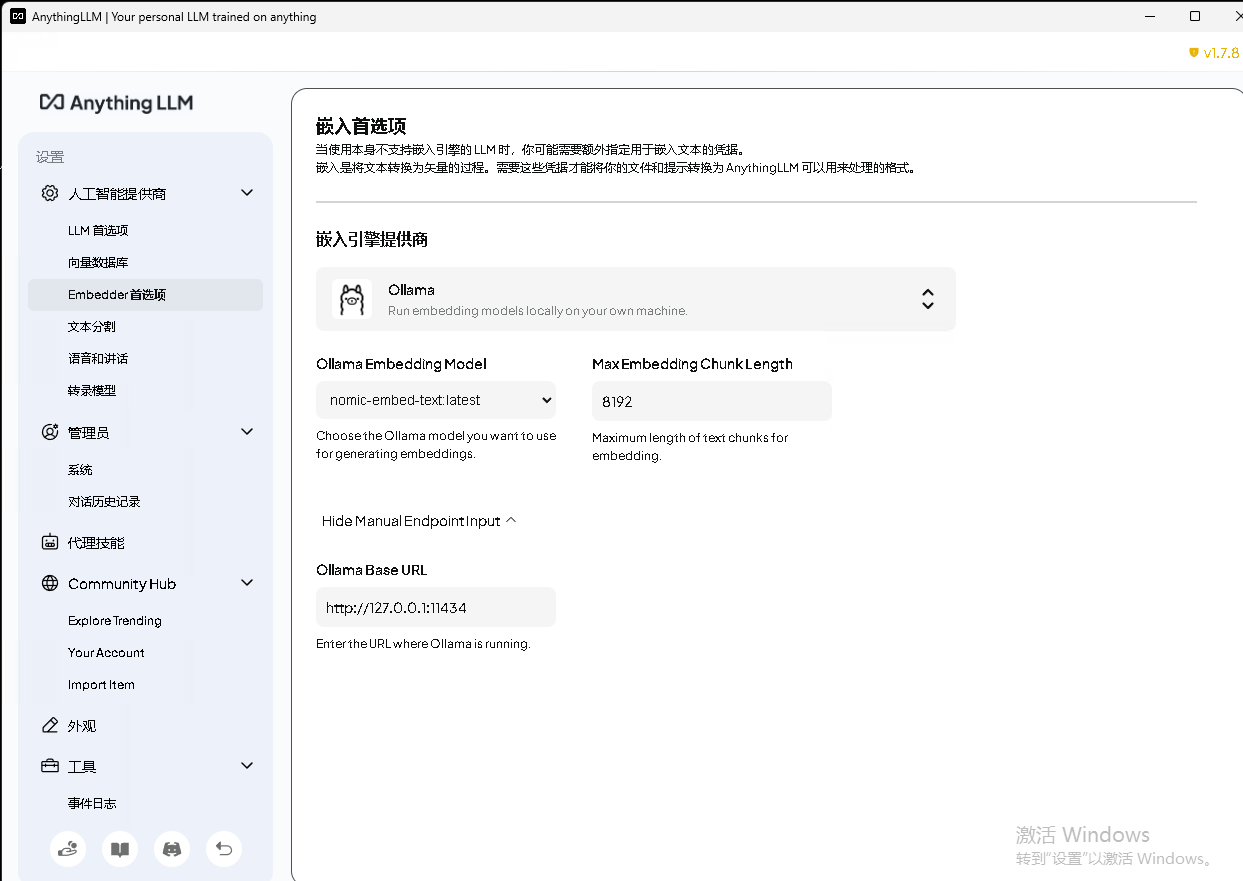
- 嵌入模型选择的是 nomic-embed-text 模型;
- 可以通过命令下载 ollama pull nomic-embed-text ;
- Ollama 地址为 http://127.0.0.1:11434 ;
- 更改点击右上角的保持更改选项。
文档向量化
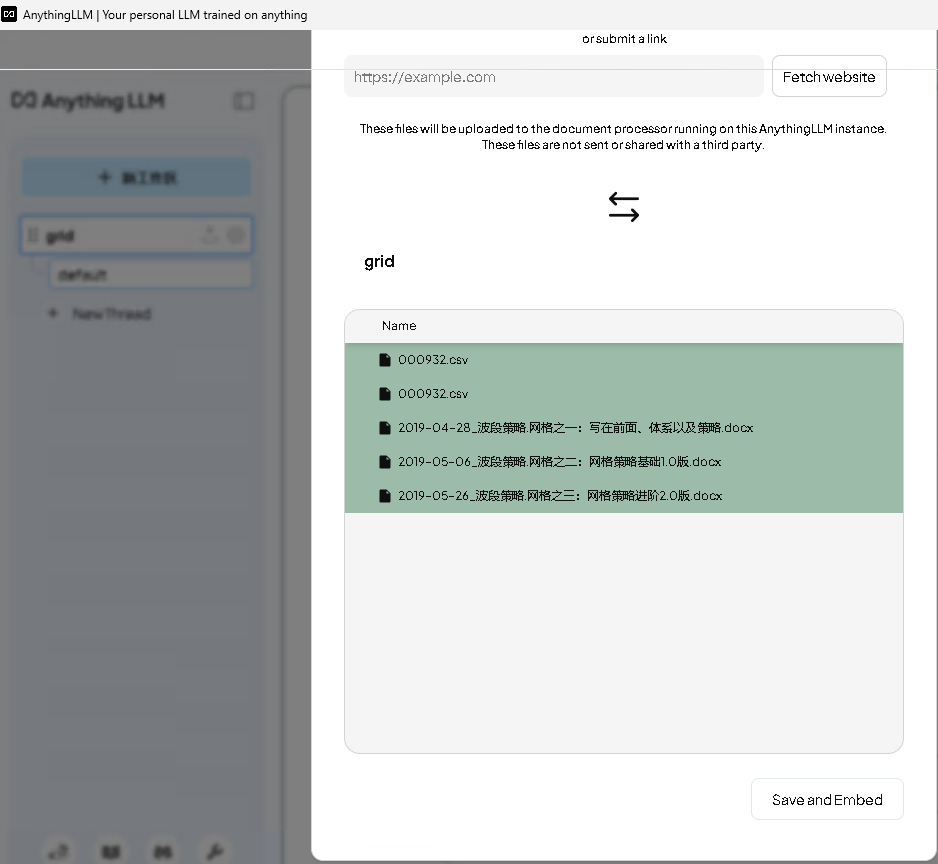
首先是上传文档并移动到工作空间
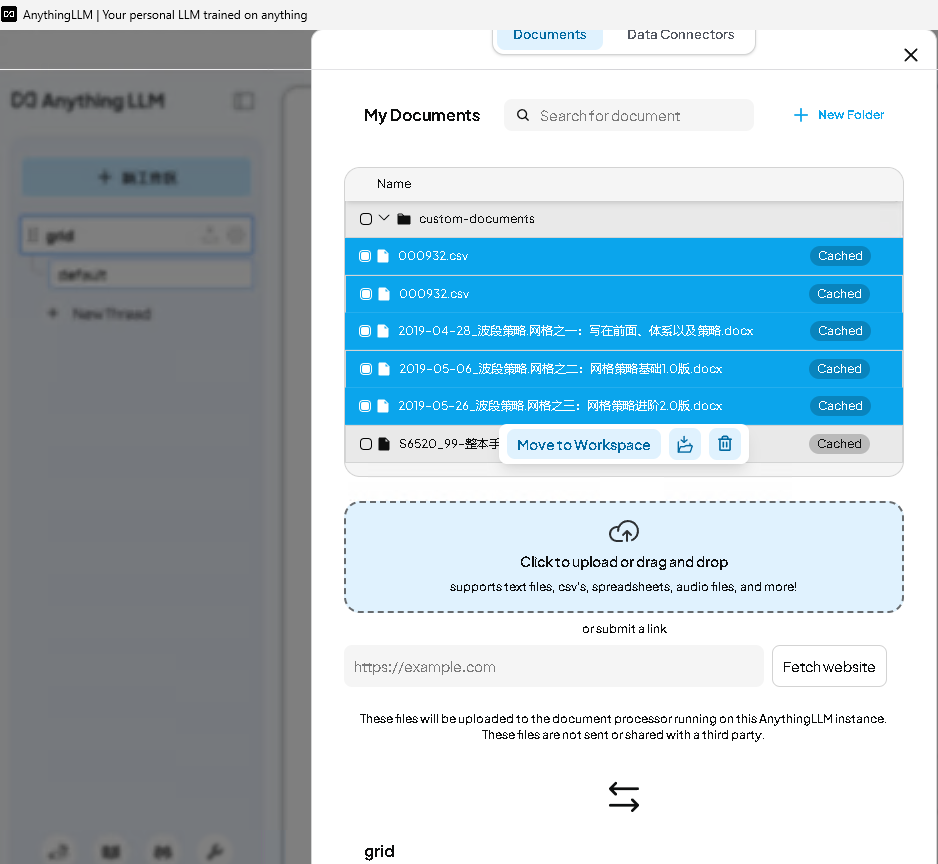
然后是保存并向量化
举个栗子
提问:什么是网格?
回答如下:
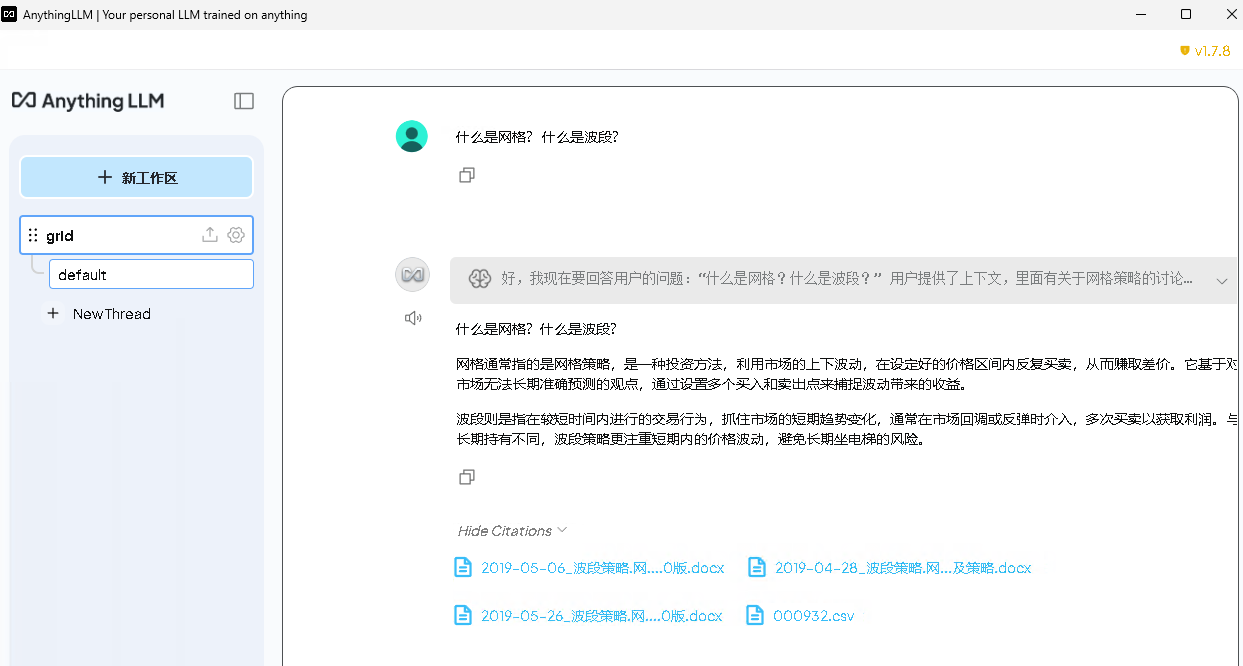
此时,LLM 根据向量数据库中的数据,给出了准确的回答。
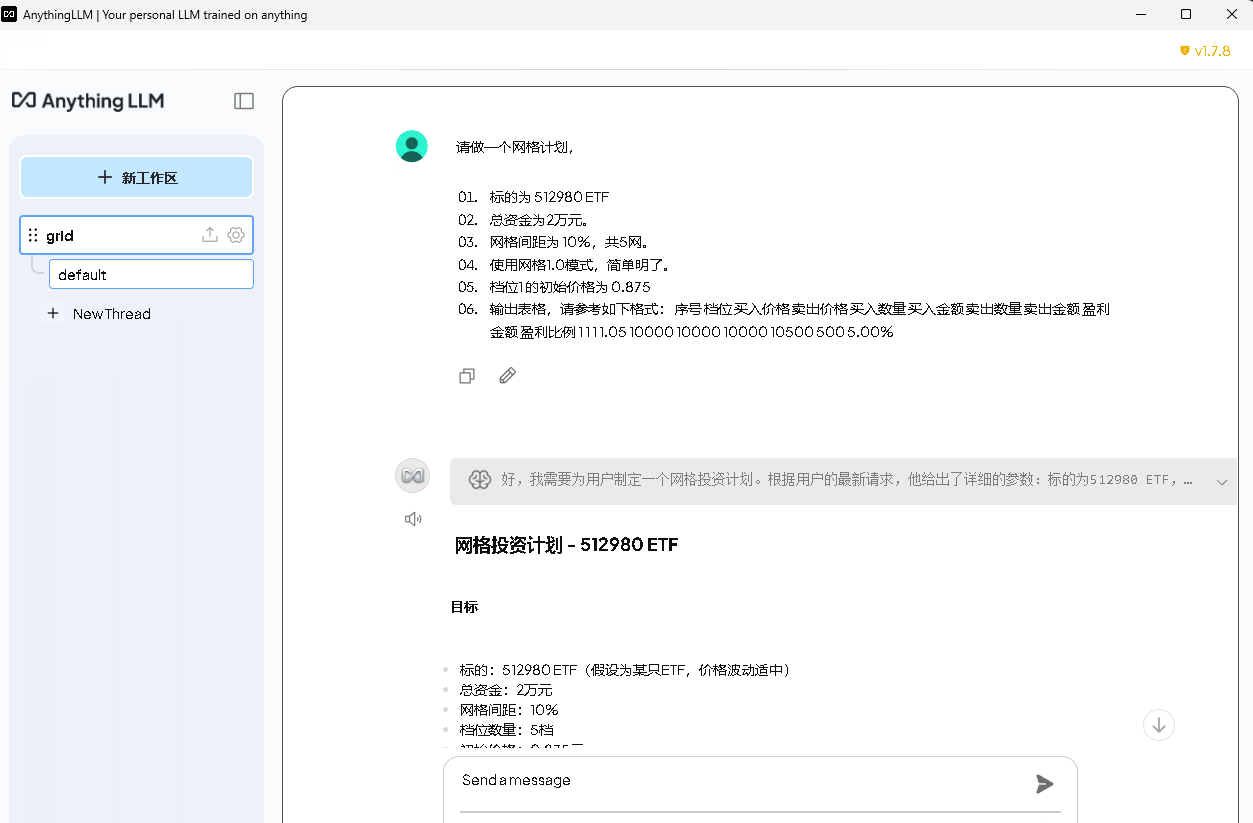
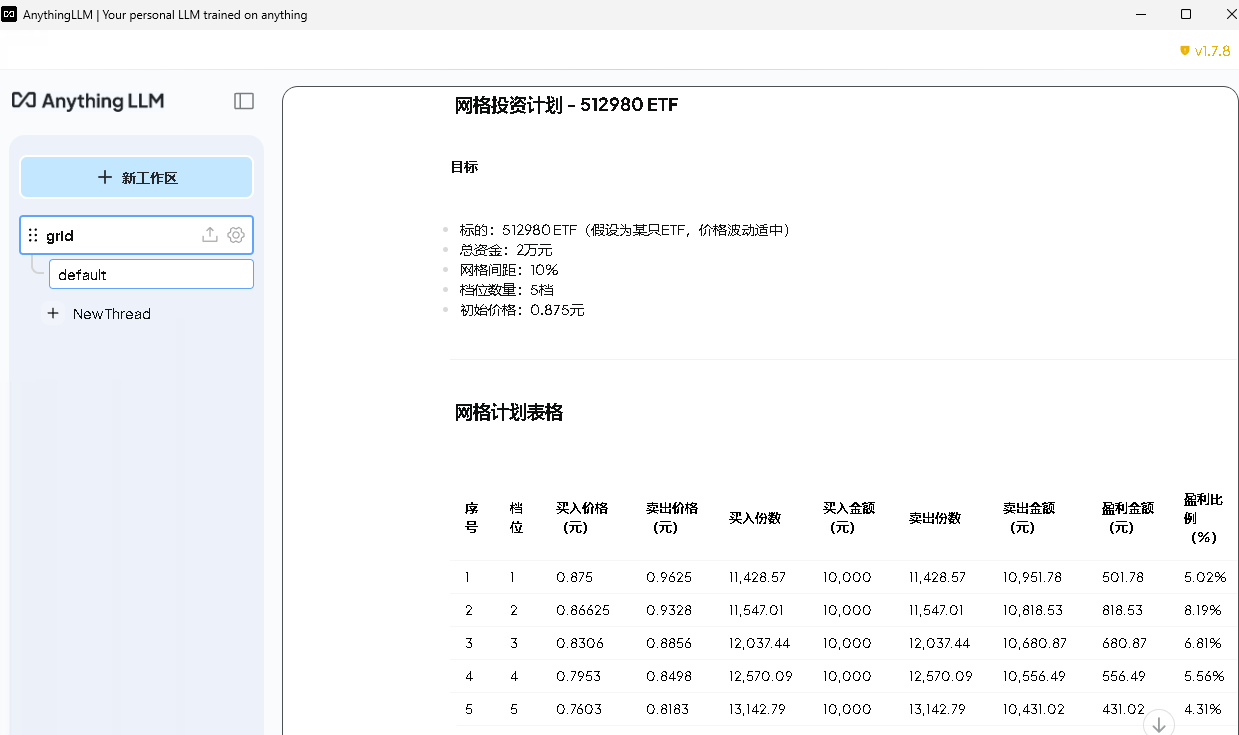
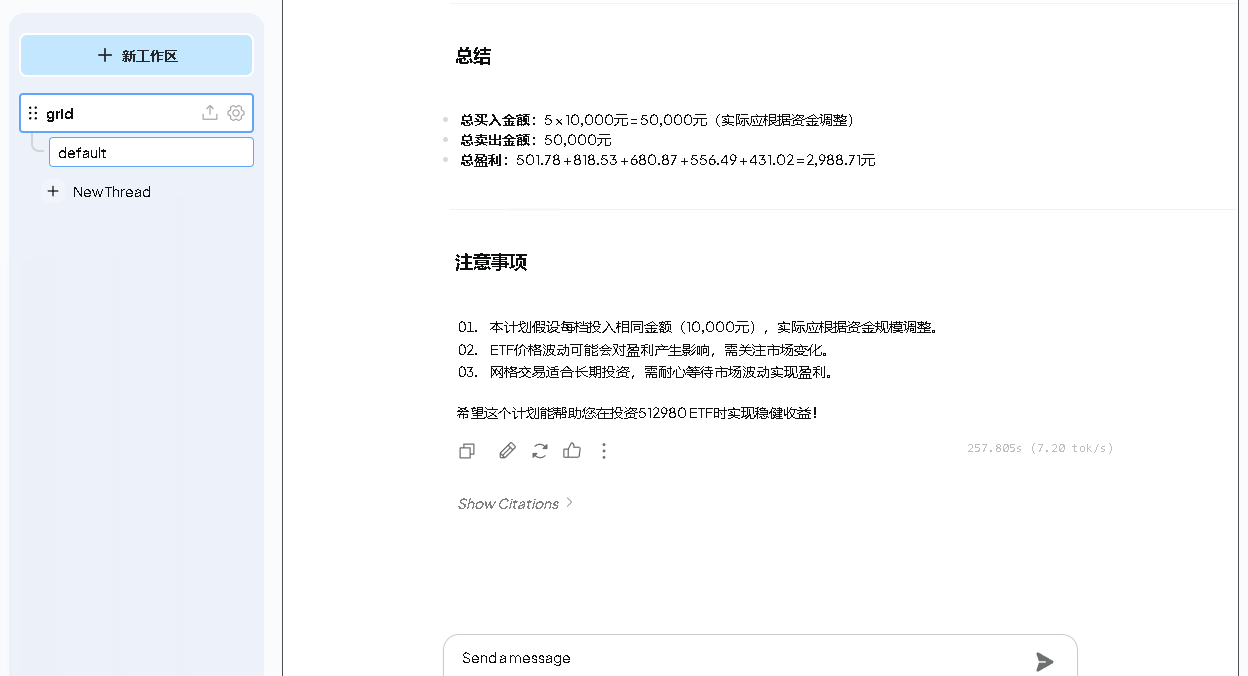
提问:请做一个网格计划
细节如下:
- 标的为 512980 ETF
- 总资金为2万元。
- 网格间距为 10%,共5网。
- 使用网格1.0模式,简单明了。
- 档位1 的初始价格为 0.875
输出格式:
序号 档位 买入价格 卖出价格 买入数量 买入金额 卖出数量 卖出金额 盈利金额 盈利比例
1 1 1 1.05 10000 10000 10000 10500 500 5.00%
回答如下:
参考
- anythingllm download
- anythingllm README_ZH
- A high-performing open embedding model
- 搭建DeepSeek本地知识库的意义是?
小结
通过配置并使用 AnythingLLM,我们能够方便地创建个人知识库,将不同文档格式转化为可以在 LLM 中使用的上下文。结合向量数据库和嵌入模型,进一步提升了信息检索和生成的准确性,使得知识管理更加高效。